Enterprise AI Coding Service: Codex Distribution, Multi-Model Access, Sub-Account Governance, and Private Deployment
Posted April 12, 2026 by XAI Product Team ‐ 19 min read
What enterprises really need is not a single AI account — it is a system that unifies domestic and international AI Coding resources, distributes them continuously, governs them precisely, and deploys wherever the business requires.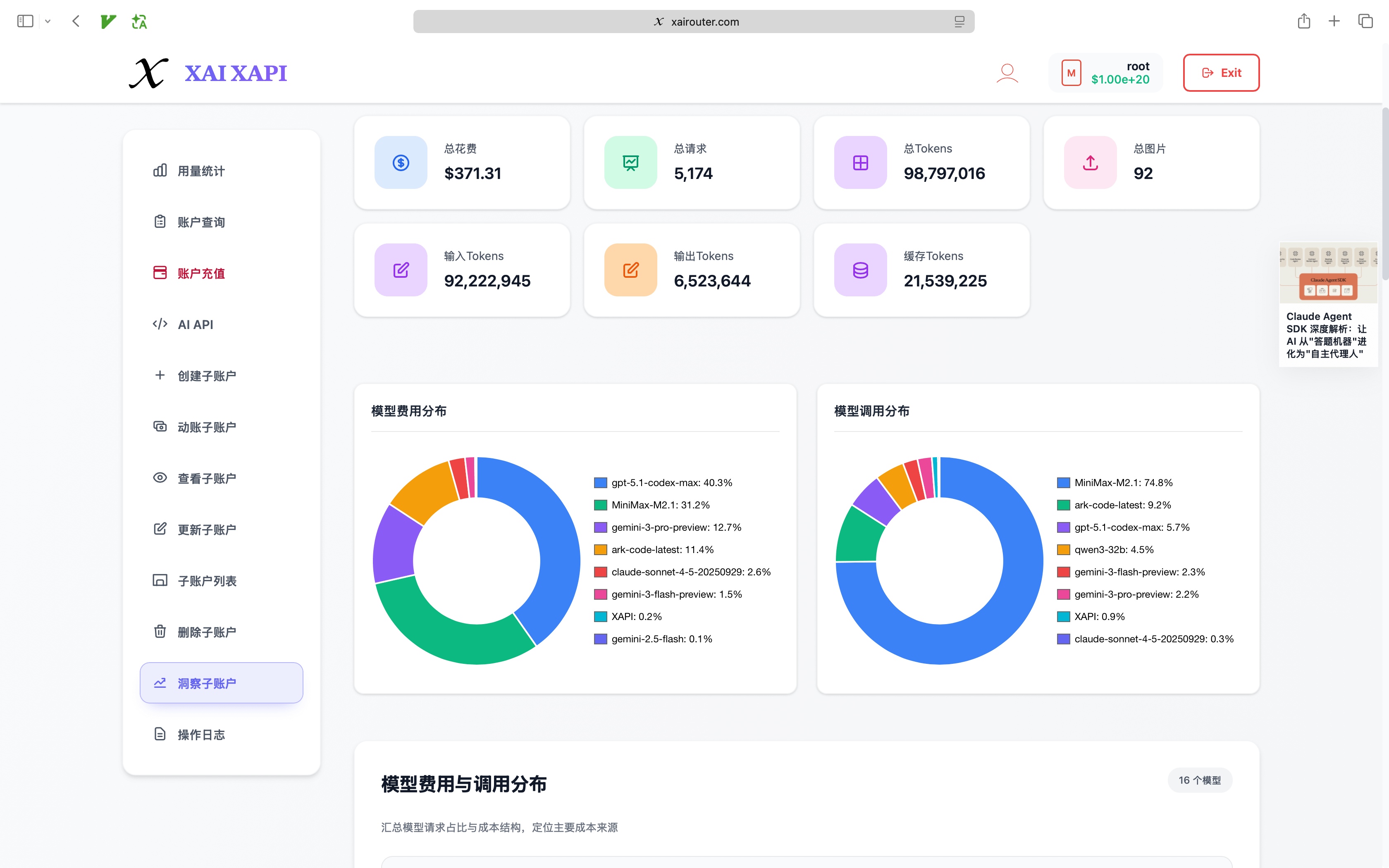
When enterprises reach out to us, the ask is remarkably consistent:
"We need a stable, controllable way to distribute Codex to our engineers. If we also want ChatGPT Pro, plus capacity from Volcengine Ark, Alibaba Cloud, Baidu Qianfan, Tencent Cloud, MiniMax, Zhipu, or Kimi Coding Plan — can it all live under one governance system? Our internal systems need a single AI API. And if usage grows, we want the option to deploy privately."
That is exactly the service we deliver.
Not a shared account. Not a login everyone fights over. A complete system:
- Codex service distribution — the enterprise can distribute Codex resources and mainstream AI APIs to employees, teams, and projects on an ongoing basis
- Unified multi-provider access through XAI Router — ChatGPT Pro, Volcengine Ark, Alibaba Cloud, Baidu Qianfan, Tencent Cloud, MiniMax, Zhipu, Kimi Coding Plan, and more, all behind one control plane
- Primary/sub-account governance — model permissions, quotas, rate limits, and analytics managed in one place
- Flexible deployment — cloud-based dedicated distribution, or private deployment of XAI Router inside the enterprise
In one sentence: the enterprise is not buying an account. It is buying an AI productivity delivery system.
Why "Buying a Few Accounts" Is Not Enough
Purchasing a handful of AI accounts may look convenient at first. Once usage enters real organizational workflows, four problems surface quickly.
1. When Accounts Sit with Individuals, the Enterprise Loses Control
Employees logging in on their own, storing credentials locally, configuring tools independently — it feels flexible until the management gaps become obvious:
- Offboarding is painful when an employee leaves
- The company cannot verify which tools still draw on the same capability pool
- AI capability cannot be distributed by department, project, or role in any structured way
- Once usage grows, the organization drifts into disorder: whoever gets an account first gets the capability first
2. A Chat UI Does Not Mean Engineering and Business Systems Are Connected
Many companies buy AI services only to find that a handful of employees can access them in a browser. The teams that actually matter — engineering, automation, internal systems, agent workflows — still have no unified entry point:
- Employees need direct Codex access for real development work
- Internal systems need a unified API gateway to call AI
- Admins need control over which models are allowed, daily quotas, and overage handling
3. Costs Rise Faster Than Budget Control Can Follow
With scattered accounts, practical questions appear quickly:
- Which departments are consuming the most AI?
- Which employees are generating real output versus simply burning tokens?
- Which calls belong on premium models, and which should fall back to lower-cost tiers?
- How should budgets be split across engineering, operations, support, and analytics?
Without a unified account system and usage analytics, AI spend becomes a growing total that gets harder to justify every month.
4. Once Security and Compliance Matter, Single-Account Thinking Breaks
Especially in engineering, finance, healthcare, government, and manufacturing, business stakeholders quickly demand:
- Upstream API keys must not be scattered to every employee
- All calls must be auditable
- Permissions must inherit along the org chart
- Data and control planes must stay inside the enterprise perimeter
At that point, "buy a few accounts" is no longer a real answer.
What This Service Delivers
1. Codex Service Distribution
The first layer is a stable, controllable Codex distribution model for the enterprise.
The value is not simply "the team can use Codex." It turns Codex into a capability the company can formally distribute, formally govern, and formally scale:
- Engineers and employees access Codex through a single, managed entry point
- Permission distribution, account governance, and capacity expansion all follow a standard path
- The company builds its own AI Coding operating model instead of inheriting individual habits
ChatGPT Pro can be governed as one high-value upstream source within this system, but it should not be the sole center of the offering.
Under the hood, our Codex bridge component achieves near-zero-rewrite passthrough for native Responses API traffic — requests from Codex CLI / App reach the upstream almost untouched, preserving OpenAI's official Prompt Caching semantics. For non-native clients like Claude Code or OpenAI Chat Completions, the bridge automatically converts requests into Codex Responses format and synthesizes a stable cache-affinity key for each request, maintaining session-level cache coherence. This means even clients that do not speak the Responses protocol can achieve near-native cache hit rates and latency performance.
2. Unified Access Across Domestic and International AI Capacity
Most enterprises do not need just one provider. They need different upstream sources for different scenarios:
- Engineering teams want Codex as their primary coding tool, with ChatGPT Pro available for high-value tasks
- Some business teams prefer domestic cloud or model providers
- The company may already hold plans from Volcengine Ark, Alibaba Cloud, Baidu Qianfan, or others and wants them governed centrally
- Management does not want employees reconfiguring separate accounts and reporting systems for every vendor
This is where XAI Router becomes more than a routing address — it becomes a unified AI resource entry point.
XAI Router's model resolution engine uses a multi-stage adaptive resolution strategy that combines exact matching, pattern scoring, and dynamic weighting to reach a routing decision in sub-millisecond time. With wildcard rules, a single claude-*=gpt-5.4 entry is enough to route all Claude-family requests to a designated Codex model. Resolved mappings are hot-cached in runtime memory, and subsequent requests for the same model name hit the cache directly without repeating the multi-stage lookup. A built-in compaction mechanism prevents cache bloat from affecting gateway performance.
Through XAI Router and its AI Provider components, the enterprise connects all upstream sources into a single control plane. Whether the source is Codex upstream capacity, ChatGPT Pro, or domestic model services, they can all:
- Be independently associated with the enterprise's dedicated primary account on the cloud-based XAI Router
- Be distributed to employees, departments, and projects via a primary/sub-account hierarchy
- Run under one consistent system for model permissions, quotas, rate limits, analytics, and audit
- Later migrate smoothly to a privately deployed XAI Router
Upstream sources can expand freely. Downstream governance stays unified.
3. Build an Enterprise Sub-Account Structure
The next layer connects everything through XAI Router into a governance structure the enterprise owns.
The real requirement is not just "the primary account works." It is that capability can be distributed, governed, and operated downward:
- The primary account controls the global AI resource pool
- Sub-accounts map to departments, project teams, roles, or individual employees
- Governance boundaries inherit downward — lower levels can narrow scope but cannot exceed parent constraints
- Distribution covers not just credits but also model permissions, rate limits, and daily caps
At the implementation level, the account hierarchy uses a graph-based organizational structure — each account holds a unique position in the org graph, and descendant queries complete in constant time through a built-in index structure, with no degradation regardless of tree depth. Governance policies propagate downward along the org graph: child accounts can narrow permission boundaries but can never exceed parent constraints. Credit and quota mutations execute atomically within transactions to guarantee consistency between parent and child accounts.
This is the point where AI stops looking like an ad hoc tool and starts resembling a governable internal resource — like budget, cloud capacity, or SaaS licenses.
4. Put Unified AI APIs Directly in the Hands of Employees
In most enterprises, the real need is not "another chat window." It is:
- Engineering teams need direct Codex access
- Internal tools need one AI API
- Support, operations, and analytics systems need one model gateway
- IT needs to know who is calling what, how much it costs, and whether limits are being exceeded
Through the primary/sub-account structure, the enterprise distributes Codex resources, ChatGPT Pro capability, and AI API access directly to employees and internal systems. What each user receives is an enterprise-governed credential — no direct exposure to complex upstream keys.
Critically, the distributed capability does not have to come from a single upstream source. Engineering uses Codex. High-value scenarios route through ChatGPT Pro. Business systems tap domestic model capacity. Automation picks model tiers by cost and stability. The enterprise keeps one account system, one policy layer, and one analytics view throughout.
From an integration perspective, the following all converge behind one gateway:
- Codex CLI / App on native
Responses(HTTP + WebSocket dual channel) - OpenAI-compatible APIs on
/v1/chat/completions - Claude-compatible access on
/v1/messages - Domestic and international model resources mapped, distributed, and governed through one enterprise entry point
- Engineering scripts, automation, internal apps, and agent services — all on one gateway
Front-end tools can be as diverse as the team needs. Back-end governance has one entry point.
Real Case: A 200-Engineer Team Cut Monthly AI Spend from RMB 100k to Under RMB 30k
A team of roughly 200 engineers kept its existing development workflow largely unchanged while reducing monthly AI Coding spend from around RMB 100,000 to under RMB 30,000 — and got a near-unlimited Codex usage experience that actually felt smoother day to day.
The key was not forcing a client switch. It was the synergy of protocol bridging and cache-affinity optimization:
- The bridge layer automatically converts Claude Code's
/v1/messagesrequests into Codex Responses format, preserving tool definitions, chain-of-thought, and full context - Stable cache-affinity key synthesis plus session-level intelligent routing gives HTTP requests cache hit rates approaching WebSocket levels
- The enterprise connected
Codexonce through XAI Router on the backend; the migration was nearly invisible to end users - Total cost dropped, effective capacity grew, and the daily developer experience improved
- Request latency and peak-hour concurrency both improved noticeably — when Prompt Caching hits, latency can drop up to 80% and input token cost can drop up to 90%
For founders, CTOs, and infrastructure leads, this case makes one thing clear: the goal is not to connect one more model. The goal is to distribute higher-value, lower-cost, smoother AI capability without disrupting the team's workflow.
5. Low-Cost, High-Concurrency, Low-Latency API Traffic for Business Systems
Employee usage is just the start. Real call volume usually comes from business systems:
- Customer support, sales assistance, outbound QA, knowledge-base Q&A
- Content generation, summarization, tagging, moderation, classification
- Operational automation, analytics workflows, batch processing, agent orchestration
- Apps, SaaS products, and internal platforms that need unified model access
These scenarios have fundamentally different requirements — low cost, high concurrency, low latency, and high stability.
XAI Router amplifies its value here. The enterprise can distribute Codex to engineering while simultaneously exposing mainstream AI APIs to business systems through one gateway for:
- Multi-model routing with intelligent failover: key pool scheduling with automatic health probing — when an upstream becomes unavailable, traffic shifts to the next available channel transparently
- Cross-level failover: model-level primary → backup → degraded multi-tier automatic switching, with configurable policies and recovery conditions
- Multi-dimensional rate control: request and token dimensions controlled independently, configurable per sub-account, supporting both single-node and distributed cluster modes
- Unified authentication, quotas, and audit
The enterprise is not just buying "AI for employees." It is also getting an AI API infrastructure layer that can enter real production workflows.
6. Optional Private Deployment
If the enterprise requires stronger control, tighter security boundaries, internal-network deployment, or long-term data sovereignty, we can deliver a privately deployed XAI Router.
The enterprise gets not only a dedicated primary account and governance model but also deploys the control plane, routing plane, and management console to its own servers, private cloud, or dedicated network.
This mode fits organizations that:
- Have hard requirements on data boundaries
- Want to own AI resources and governance logic for the long term
- Refuse to place critical management operations in a third-party public environment
- Are ready to move AI from trial usage into internal infrastructure
For these customers, private deployment is not "the more complicated version." It is the point where AI becomes part of the enterprise production system.
Technical Architecture: Why We Can Deliver This
When evaluating AI middleware, many enterprises ask: there are plenty of API gateways and routing services out there — what makes yours different?
The answer is that we did not bolt a few features onto a generic gateway. We built a purpose-designed three-layer architecture for enterprise AI scenarios from the ground up.
Control Plane: Organization, Policy, and Resource Allocation
The control plane handles "who can use what, how much, and how it is governed."
- Graph-based account hierarchy — an unbounded org tree where descendant queries complete in constant time through a built-in index structure, with no degradation as depth increases
- Policy inheritance along the graph — model permissions, mapping rules, rate limits, and daily quotas all propagate parent → child; children can narrow but never exceed parent boundaries
- Dual-track billing — financial credit balances (subscription / pay-as-you-go / add-on packs) and business usage quotas tracked in parallel, with multi-window quota reclamation and bucket management
- Hot-reload configuration — tenant config changes take effect within minutes, no gateway restart required; multi-node deployments stay consistent through a coordination protocol
Runtime Routing Plane: Model Resolution, Key Scheduling, and Rate Control
The runtime routing plane handles "where each request goes, how fast, and how reliably."
Intelligent Model Resolution
A multi-stage adaptive resolution strategy combines exact matching, pattern scoring, and dynamic weighting to reach a routing decision in sub-millisecond time. Resolved results are hot-cached in runtime memory and kept bounded by an automatic compaction policy. Enterprises only need to configure simple mapping rules; the system handles optimal routing automatically.
Key Pools and Failover
Each tenant maintains an independent Provider Key pool, with the scheduling algorithm factoring in availability, latency, and historical performance. When an upstream returns an error, the key automatically enters cooldown with a timed recovery; when an upstream account is deactivated, the key is safely removed. In distributed deployments, gateway nodes share key state through a consistency protocol. Model-level failover supports primary → backup → degraded multi-tier switching, with configurable auto-recovery conditions.
Multi-Dimensional Rate Control
Request and token dimensions are controlled independently, with minute / hour / day time windows. Single-node deployments use high-performance local counters; distributed deployments use distributed counting primitives that guarantee global cross-node consistency. Subscription-type accounts can be configured to automatically switch to pay-as-you-go mode when quotas are exhausted.
Multi-Tier Cache Hierarchy
All hot-path data follows a multi-tier caching strategy — in-process memory as the first tier, distributed cache as the second, and persistent storage as the last resort. Model mapping and level mapping use dedicated hot-path caches; usage statistics are first aggregated in memory, then flushed asynchronously in batches to the persistent layer, balancing real-time accuracy with throughput.
Protocol Bridge Plane: Letting Different Clients Share One Governance System
The protocol bridge plane is the key differentiator between XAI Router and a generic API gateway.
Ordinary gateways forward URLs. We enable clients speaking different protocols to share one unified governance layer while preserving upstream semantics.
Native Codex Path
Codex CLI / App requests to /v1/responses (HTTP and WebSocket) go through near-zero-rewrite passthrough. The bridge performs only the minimum necessary: injecting identity markers, synchronizing session context, and propagating cache control parameters. WebSocket connections follow official OpenAI semantics, with Responses and Realtime modes sharing a unified connection management framework.
Cross-Protocol Semantic Conversion
When Claude Code sends /v1/messages, or other clients send /v1/chat/completions, the bridge component performs a complete conversion to Codex Responses format:
- Message structures, tool definitions, and content blocks are individually mapped with full semantic preservation
- Tool definitions undergo deep normalization to ensure correct upstream parsing
- Streaming responses are processed through a proprietary event-stream aggregation engine — multi-stage snapshot data is merged in real time, output items are backfilled in order, and a complete target-format stream is synthesized
- Each request automatically receives a stable cache-affinity key, giving HTTP requests Prompt Caching performance benefits
Security Architecture
- Upstream Provider Keys are stored using an end-to-end encryption scheme with key material derived from the user's own credentials — the platform never holds plaintext at any point
- Lookup is performed through a partial-feature index; decryption occurs only in an isolated memory space
- Before forwarding, the gateway automatically strips all headers that could leak internal topology
- A multi-layer ACL pipeline covers authentication, origin verification, model permissions, resource permissions, account status, and quota checks, each layer independently configurable
What This Means for Three Enterprise Roles
For Owners and Senior Management
Not a handful of scattered accounts — an AI resource system that can actually be operated:
- AI capability distributed continuously through the org chart
- Cost visible by account, department, model, and time period
- Usage no longer a black box
- Domestic and international providers used in parallel — no single-vendor lock-in
- One system that supports both engineering
Codexuse and large-scale business API traffic - Scaling investment does not require rebuilding from scratch
For IT and Digital Infrastructure Leaders
A unified control plane:
- Sub-account hierarchy that maps to org structure — descendant queries across any depth complete in milliseconds
- Model permissions, mapping rules, tier strategy, rate limits, and quotas governed centrally
- No upstream keys scattered to employee endpoints — upstream credentials encrypted end-to-end, clear permission boundaries
- Adding new model providers takes one wildcard mapping rule, no new governance framework needed
- One gateway for both employee tool traffic and business-system traffic
- A continuous path from managed cloud to private deployment — hot-reload configuration, zero-downtime transitions
For Engineering and Business Teams
AI capability that fits real workflows — not a demo-only chat window:
- Developers use Codex directly — native Responses path with near-zero rewrite, no loss of Prompt Caching performance
- Claude Code connects seamlessly —
/v1/messagesauto-bridged to Codex Responses, zero configuration on the user side - Internal tools and services connect through unified APIs; existing OpenAI / Claude integrations migrate gradually
- Different model resources are assigned into the same workflow based on team needs
- Business systems choose AI APIs by cost, latency, and stability targets
- No one needs to maintain complex upstream configuration by hand
Not a Slide Deck — An Operable Enterprise Delivery Chain
This is not a conceptual diagram. The product already has the shape of real infrastructure:
- XAI Router serves as the control plane and runtime routing plane — primary/sub-account hierarchy, graph-based inheritance, intelligent model resolution, key pool scheduling, multi-dimensional rate control, dual-track billing, hot-reload configuration, and management console
- Codex-Cloud serves as the protocol bridge plane — complete protocol conversion for Chat Completions / Claude Messages / native Responses, cache-affinity key synthesis, credential secure rotation, streaming event aggregation, and WebSocket dual-channel support
- AI Provider components connecting different upstream resources — ChatGPT Pro, OpenAI-compatible APIs, Claude-compatible paths, and domestic and international model services
- Management console with top-up, AI API access, sub-account management (list, create, inspect, update, delete), and sub-account insights
The entire system has been continuously performance-tuned: high-performance memory allocation, connection reuse with persistent connections, HTTP/2 adaptive flow control, and all hot-path data served from in-memory caches. The gateway maintains sub-millisecond routing decision latency under thousands of concurrent requests.
When an enterprise buys this service, it is not buying a drawing. It is buying a running system that can be delivered, managed, and expanded.
Recommended Adoption Path: Start Fast, Then Gradually Tighten Governance
No enterprise needs private deployment on day one. No enterprise needs every employee standardized on day one either. A more realistic path:
- Deliver Codex service distribution so the core team can start immediately
- Connect existing or planned AI resources into XAI Router
- Build the primary/sub-account structure and distribute Codex plus unified AI APIs to more employees
- As usage grows, layer in model permissions, rate limits, budget controls, and audit
- When security and control requirements escalate, move to private deployment
The advantage is simple: start today without creating a rebuild problem tomorrow.
Which Enterprises Fit Best
This model typically works better than buying isolated accounts if:
- You want to formally distribute Codex across the enterprise without leaving control in individual hands
- You already have, or plan to buy, resources from multiple domestic and international AI providers and want unified access and distribution
- You want tens or hundreds of employees using Codex or unified AI APIs
- You have both employee-side AI Coding needs and business-system-side high-volume API traffic
- Engineering, operations, support, and analytics teams need to share one governance framework
- You need sub-account distribution, quota boundaries, model permissions, and usage analytics
- You expect to move toward private deployment or dedicated network deployment later
Conclusion
For enterprises, the real question was never "did we buy an AI account?"
The real questions are:
- Can AI capability be delivered stably into the organization?
- Can resources be distributed continuously to employees and systems?
- Can cost, permissions, and risk be controlled?
- Can the whole thing keep evolving as the business scales — without being rebuilt from scratch?
That is exactly what this service solves.
Codex service distribution is the starting point closest to day-to-day enterprise reality. From there, XAI Router lets the enterprise unify mainstream domestic and international AI Coding resources into one primary/sub-account system, putting Codex and mainstream AI APIs directly into the hands of employees and business systems — supporting both high-value engineering coding scenarios and low-cost, high-concurrency, low-latency production traffic. As the business matures, private deployment of XAI Router gives the enterprise full control over its AI resources and governance.
If you are looking for an AI delivery model that can land quickly today and remain governable tomorrow, this is a far more sustainable answer than buying scattered accounts.